
Dane strukturalne to semantyczne znaczniki w kodzie, użyte w celu przekazania dodatkowych informacji w umówiony wcześniej sposób. Pozwala to na łatwiejsze przetwarzanie informacji zawartych na stronie www przez programy co ułatwia ich prezentowanie dla użytkownika końcowego po przetworzeniu. Poprawna implementacja danych strukturalnych na stronie internetowej pozwala na przetworzenie ich np. przez wyszukiwarkę Google i prezentację wyników wyszukiwania uzupełnionych o opisy rozszerzone (Rich Snippets). W przypadku Social Media, dane strukturalne mogą decydować o tym jak będzie prezentowana nasza strona www w momencie udostępnienia.
Za danymi strukturalnymi stoi idea sieci semantycznej i uzupełniania danych na stronach o dodatkowe informacje bez modyfikacji języka i wyglądu strony. Dane te są łatwo odczytywane, łączone i przetwarzane przez programy. Wszystko w celu łatwiejszego i bardziej trafnego wyszukiwania, przetwarzania i prezentowania informacji. Algorytm nie musi analizować całego tekstu w celu łączenia poszczególnych elementów, rozpoznaje je na podstawie informacji wskazanych przez dane strukturalne.
Jakie dane strukturalne umieścić na naszej stronie www?
Skupmy się wyłącznie na tych danych strukturalnych, które można umieścić na stronie internetowej i nie wpływają one w żaden sposób na wyświetlanie strony użytkownikowi końcowemu. Ich implementacja może natomiast wpłynąć m.in. na wygląd strony www w wynikach wyszukiwania (SERP), oraz w mediach społecznościowych w momencie udostępnienia.
Pierwszym ważnym elementem, na który mogą wpłynąć dane strukturalne są tzw. Rich Snippets, czyli opisy rozszerzone widoczne w wyszukiwarce Google. Ułatwiają one przetworzenie i zrozumienie elementów na stronie internetowej. Dzięki temu Google może ulepszyć SERP o dodatkowe dane zaimportowane ze strony www. Przykładowo, wynik może zostać uzupełniony o nadchodzące wydarzenia, ocenę produktu, Breadcrumbs Trail lub zakres świadczonych cen.

Należy pamiętać, że zgodnie z ideą sieci semantycznej, wszystkie dane są łączone, również te które znajdują się na obcych stronach. Może to mieć skutek w postaci dodatkowych danych pod kartą informacyjną zaimportowanych z witryny zewnętrznej, np. Facebooka czy Goldenline.

Na uzupełnianiu SERPów o dodatkowe dane korzystają wszyscy, zarówno Google - zatrzymujący użytkownika na dłużej na stronie wyszukiwania - jak i sam użytkownik, który dostaje bardziej wyczerpujące dane. Natomiast właściciel strony ma więcej możliwości zaprezentowania swojej firmy i wyróżnienia się na tle konkurencji, a tym samym do zachęcenia i kliknięcia, a więc zwiększenia CTRu. Wyniki uzupełnione o dodatkowe dane strukturalne mają oczywistą przewagę nad wynikami prezentującymi jedynie title, description i adres strony www.
Niewątpliwą wadą jest jak zwykle – uznaniowość Google w kwestii tego jak i czy nasze mikrodane zostaną w ogóle wykorzystane. Kompleksowe wdrożenie mikrodanych na stronie intrnetowych nigdy nie gwarantuje nam określonego wyświetlania w SERPach i należy się z tym liczyć.
Kolejnym możliwym efektem uzupełnienia danych strukturalnych, w tym przypadku Open Graph, jest wpływanie na to jak nasza strona www zostanie wyświetlona w momencie udostępnienia w Social Media, czyli np. na facebookowym wallu czy w kartach Twittera. W przypadku braku danych strukturalnych Open Graph, algorytm wybiera jedynie podstawowe tagi takie jak title i description i na ich podstawie buduje kartę. Rodzi to dwa potencjalne problemy. Po pierwsze, to co sprawdza się w SEO (title) i w SERPach (description), niekoniecznie będzie się sprawdzać w Social Mediach. Drugim i często większym problemem jest automatyczne dobieranie danych - nie mamy więc wpływu czy i jaka miniatura zostanie wybrana jako reprezentacja naszej strony. Ograniczamy również ilość zaimportowanych danych do tych, które algorytm może określić automatycznie.
Przykładowa strona pozbawiona danych strukturalnych Open Graph udostępniona na Faceboooku:

Ta sama strona w Social Mediach po uzupełnieniu danych strukturalnych Open Graph:

Z jakich danych strukturalnych należy korzystać?
W przypadku danych strukturalnych dla wyszukiwarek, warto skupić się na słowniku schema.org interpretowanym przez Google, który można wykorzystać zależnie od potrzeby za pomocą formatów RFDa, Microdataalbo lub JSON-LD. Jaki format wybierzemy, zależy od sytuacji i osobistych preferencji. Poniższe przykłady zostaną omówione na przykładzie mikrodanych (Microdata), które są najpopularniejszym formatem według badań Web Data Commons z 2016 roku
Słownik mikrodanych schema.org można podzielić na 3 elementy: typy, właściwości i wartości. Każdy typ mikrodanych musi mieć zdefiniowany adres słownika w kodzie aby został prawidłowo rozpoznany. Ponadto typ posiada właściwości które są wymagane, aby go prawidłowo zinterpretować co zostanie omówione później.
W przypadku portali społecznościowych wszystko zależy od tego na jakich kanałach się skupiamy. Bezsensowne jest uzupełnianie kodu o dane, które nie zostaną prawdopodobnie nigdy wykorzystane. Dużym ułatwieniem jest kompatybilność z Open Graph kilku portali jednocześnie i dane, które przygotujemy dla Facebooka (będą również prawidłowo interpretowane przez Twittera).
Przykładowe wykorzystanie danych strukturalnych w SERP przez Google:
Zastąpienie adresu podstrony za pomocą Breadcrumbs Trail:

Wyświetlenie ceny produktu, usługi albo nieruchomości:

Lista nadchodzących wydarzeń które znajdują się na stronie wraz z datami:

Podstrony oraz wyszukiwarka onsite dostępna bezpośrednio z wyników Google:
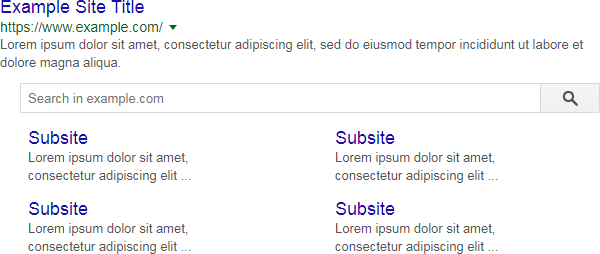
Wyświetlenie oceny, a także danych na temat aplikacji:

Przykładowa implementacja krok po kroku z użyciem typu LocalBusiness, słownika schema.org i mikrodanych:
Implementacja jest bardzo prosta. Za przykład posłużą dane kontaktowe, które wskazują na naszej stronie konkretną firmę. Należy wskazać prawdziwe wartości, a jeśli nie wyczerpujemy wymagań danego typu mikrodanych - uzupełnić go o brakujące. Bez podstawowych wartości, typ prawdopodobnie nie zostanie w ogóle odczytany przez Google.
Nasz początkowy kod wygląda następująco:
<div>
<p>Agencja Interaktywna Empressia</p>
<p>ul. Ziębicka 35</p>
<p>60-164 Poznań</p>
<p>Tel. +48 61 862 87 50</p>
<p>E-mail: Ten adres pocztowy jest chroniony przed spamowaniem. Aby go zobaczyć, konieczne jest włączenie w przeglądarce obsługi JavaScript.</p>
</div>
Z racji tego, że dane uporządkowane implementujemy do kodu html, sposób określania atrybutów i ich zagnieżdżanie są identyczne. Należy w znaczniku zamykającym wszystkie elementy z właściwościami umieścić deklarację typu oraz bezpośredni odnośnik do słownika. W tym przypadku do http://schema.org/LocalBusiness . Należy pamiętać, że w przypadku Mikrodanych każdy typ musi zawierać adres, inaczej nie będzie prawidłowo odczytany.
<div itemscope itemtype=" http://schema.org/LocalBusiness ">
Za dane adresowe w typie LocalBusiness odpowiada właściwość address, którą zgodnie ze specyfikacją, możemy uzupełnić na dwa sposoby. Jeden, prostszy to dowolny ciąg tekstowy, drugi, to kolejny typ PostalAddress, którego zakres należy zaznaczyć w kodzie i uzupełnić właściwościami takimi jak kod pocztowy czy telefon według dokumentacji.
Oznaczymy również kolejne elementy które znajdują się w kodzie:
<div itemscope itemtype=" http://schema.org/LocalBusiness ">
<p itemprop="name">Agencja Interaktywna Empressia</p>
<div itemprop="address" itemscope itemtype=" http://schema.org/PostalAddress ">
<p itemprop="streetAddress">ul. Ziębicka 35</p>
<p>
<span itemprop="postalCode">60-164</span>
<span itemprop="addressLocality">Poznań</span>
</p>
<p>Tel. <span itemprop="telephone">+48 61 862 87 50</span></p>
<p>E-mail: <span itemprop="email">Ten adres pocztowy jest chroniony przed spamowaniem. Aby go zobaczyć, konieczne jest włączenie w przeglądarce obsługi JavaScript.</span></p>
</div>
</div>
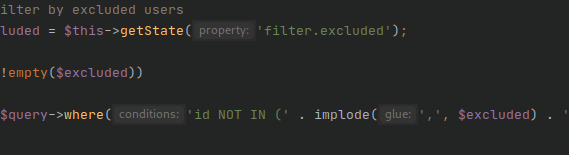
Kod zawsze warto zwalidować na stronie: https://search.google.com/structured-data/testing-tool/u/0/ . Kod nad którym pracujemy zwróci nam błędy, ponieważ brakuje nam wcześniej wspominanych właściwości wymaganych przez typ LocalBusiness. Nieuzupełnienie właściwości wymaganych uniemożliwi prawidłowe przetworzenie danego typu mikrodanych, warto jednak również uzupełnić właściwości zalecane, jeśli mamy taką możliwość. Część z nich jest wyświetlana w SERPach, np. zakres cen.
W przypadku typu LocalBusiness z naszego przykładu, wymagane są 2 właściwości: name i image, natomiast address, priceRange i telephone są właściwościami zalecanymi. Oczywiście, im więcej danych tym lepiej, nie warto się ograniczać do wartości wymaganych, a najlepiej uzupełnić wszystkie znane informacje. Niestety, nie każda właściwość jest wyświetlana w SERPach, duża część typów i właściwości służy min. łatwiejszemu zrozumieniu strony przez roboty, czy łączeniu informacji z różnych stron.
Wracając do naszego przykładu, musimy uzupełnić Mikrodane o właściwość image. W przypadku localBussiness powinno to być zdjęcie lokalizacji firmy czy pracowników. W momencie gdy danej właściwości nie mamy w tekście, a chcemy rozbudować nasz typ należy skorzystać ze znaczników meta, tak aby wygląd strony dla użytkownika pozostał niezmieniony. Po uzupełnieniu o tą, a także kilka dodatkowych właściwości, nasz typ może wyglądać następująco:
<div itemscope itemtype=" http://schema.org/LocalBusiness ">
<meta itemprop="image"
content=" https://www.empressia.pl/images/o-nas/agencja-interaktywna-sklad.jpg ">
<meta itemprop="url" content=" http://www.empressia.pl/ " >
<meta itemprop="logo" content=" https://www.empressia.pl/logo-empressia.svg ">
<meta itemprop="priceRange" content="350+ PLN" >
<div itemprop="geo" itemscope itemtype=" http://schema.org/GeoCoordinates ">
<meta itemprop="latitude" content="52.3834359" >
<meta itemprop="longitude" content="16.8438963" >
</div>
<p itemprop="name">Agencja Interaktywna Empressia</p>
<div itemprop="address" itemscope itemtype=" http://schema.org/PostalAddress ">
<p itemprop="streetAddress">ul. Ziębicka 35</p>
<p>
<span itemprop="postalCode">60-164</span>
<span itemprop="addressLocality">Poznań</span>
</p>
<p>Tel. <span itemprop="telephone">+48 61 862 87 50</span></p>
<p>E-mail: <span itemprop="email">Ten adres pocztowy jest chroniony przed spamowaniem. Aby go zobaczyć, konieczne jest włączenie w przeglądarce obsługi JavaScript.</span></p>
</div>
</div>
Jak widać, typ został uzupełniony o dodatkowe informacje, takie jak: logo, lokalizację czy zakres cen. Niektóre z tych informacji mogą się pojawić jako Rich Snippets w SERPach.
Należy pamiętać jednak, że Google, również w przypadku mikrodanych, nie znosi manipulacji i oszukiwania. Należy unikać dodawania nieistotnych znaczników, fałszywych opinii lub używania ich niezgodnie z przeznaczeniem. Według oficjalnych komunikatów na Googleblogu użycie niezgodne z przeznaczeniem, na przykład użycie typu event w celu wyświetlenia promocji, może zakończyć się karą ręczną.
Kilka narzędzi pomocnych w trakcie pracy nad znacznikami.
W implementacji danych strukturalnych pomocne będą:
- http://schema.org/ - kompletny słownik danych strukturalnych wykorzystywanych przez Google, zawiera również przykłady implementacji oraz elementy niestandardowe. Ponadto jest uzupełniany o specjalne rozszerzenia dla konkretnych branż, np. health-lifesci, który określa min. dane szpitali i placówek medycznych. Rozbudowują one już istniejące typy takie jak np. LocalBusiness, które domyślnie żadnych danych medycznych nie posiadały.
- https://search.google.com/structured-data/testing-tool/u/0/ - narzędzie Google do testowania danych uporządkowanych. Podstawowy i najważniejszy walidator naszych prac. Pozwala wychwycić wszystkie błędy które uniemożliwią odczytanie naszych danych strukturalnych przez roboty Google. Mamy możliwość testowania zarówno konkretnego adresu jak i fragmentu przygotowanego wcześniej kodu. Narzędzie umożliwia również ograniczoną opcję podglądu danych po uzupełnieniu.
- https://webmaster.yandex.com/tools/microtest/ - narzędzie o funkcji analogicznej jak walidator Google, jednak bardziej wrażliwe na nieprawidłowe formatowanie czy wielkości liter, z którymi roboty Google teoretycznie powinny sobie poradzić. Warto używać jeśli zależy nam na pedantycznej wręcz poprawności mikrodanych.
- http://ogp.me/ - dokumentacja formatu Open Graph wykorzystywanego przez Facebooka. Przydaje się zwłaszcza na początku, jednak ilość tagów które Open Graph wykorzystuje jest niewielka i są one łatwe do opanowania, a sama dokumentacja nie zawiera wyczerpujących przykładów jak w przypadku schema.org.
- https://cards-dev.twitter.com/validator - walidator kart Twittera, pozwalający na szybki podgląd wyglądu naszej strony www podczas udostępniania. Wymaga uzupełnienia Open Graph na stronie.
- https://www.google.com/webmasters/tools/structured-data - Google Search Console posiada klika interesujących zakładek pomocnych przy implementacji danych strukturalnych na stronie. Najważniejszą z nich jest pozycja Dane uporządkowane, pokazująca raport jaki typ danych, o jakim źródle i w jakiej ilości został odnaleziony na stronie przez roboty Google. Pokazywane są również wszystkie błędnie odczytane dane strukturalne. Raport generuje się z kilkudniowym opóźnieniem, jednak jest to najprostszy i najpewniejszy sposób aby kontrolować i sprawdzać poprawność danych na całej witrynie.
Co dalej?
W ciągu ostatnich miesięcy Google zwraca coraz większą uwagę w komunikatach na znaczenie danych strukturalnych. Sama biblioteka schema.org jest ciągle rozbudowywana, tak aby móc połączyć jeszcze więcej ważnych dla wyszukiwarek i użytkownika mikrodanych. Również wygląd wyników wyszukiwania zmienia się nieustannie. W momencie pisania artykułu, Google zaczęło wdrażać Direct Answer z użyciem odpowiedzi z for i serwisów społecznościowych. W związku z tym, nawet jeśli nie interesuje nas kompleksowe wdrażanie danych strukturalnych na stronach www, tematem warto zainteresować się chociażby po to aby nie odstawać na tle konkurencji.


{kind=link}
{kind=link}